

Google is not the Internet, it is an index of everything on the Internet.
In the beginning of the Internet the creator of the Internet, Tim Berners-Lee, compiled a virtual library (vlib.org) of all websites. This was manually written. I remember this directory being available in a printed paper form.
Click here for this week’s music.


The format of vlib was like a Table of Contents in a book, grouping websites into categories. Obviously, vlib could not keep up with the exponential growth of the Internet.

In 1995 Digital Equipment Corporation (DEC) launched AltaVista search engine at altavista.digital.com.
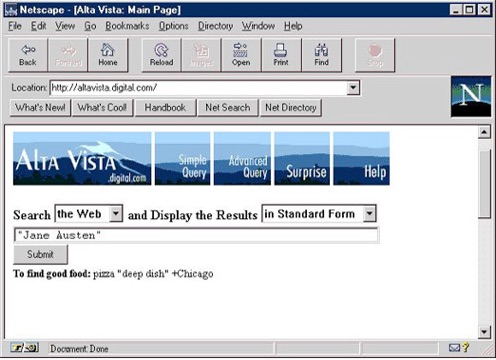
AltaVista was also organized by category, but allowed users to search for keywords within websites. This searchable index (like the index in the back of a book) was so useful that AltaVista attracted millions of web surfers every day.
In 1998 Digital was acquired by Compaq. Compaq’s Internet division changed AltaVista’s simple search page to a busy, complicated, commercial portal to the Internet. This design persisted when AltaVista was sold to Yahoo. The portal design was copied by AOL, Microsoft and many Internet service providers.
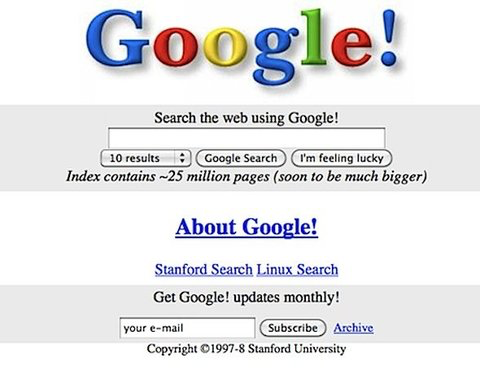
Web users missed the simple search form and began gravitating in 1998 to the new search engine, Google. Google had, as it still does today, a single, clean search field.
Google is a true searchable index of the Internet. A Googol is the number one followed by 100 zeros. 10,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,000,
000,000,000,000,000,000,000,000,000,000,000,000,000.
Google is well on its way to living up to its name with 1.2 sextillion bits of data stored for search. That is about one fifth of a Googol.
Google stores more data than what is in their search index. They also provide data heavy services like Gmail, photo storage, Google Docs, Android mobile operating system, Chrome browser, Maps, News, AI and more.
Google’s stated mission is to: “… organize the world’s information and make it universally accessible and useful.”
How does Google go about achieving this goal?
Google is constantly visiting every web page on the Internet. Software programs called “crawlers” visit web pages and record every meaningful word they find. These words are brought back to Google’s servers and added to the index.

Once words are collected on a web page the crawler follows every link on that web page and collects information wherever the links take them.
Crawlers also notice which sites change, which are new and if they contain dead links.
Additionally, the coding of a web page is observed to see if there is useful information within.
When you search, Google must look through hundreds of millions of words in their index.
Artificial Intelligence algorithms consider various aspects of your query.

The meaning of your question is your intent. After correcting spelling errors, the context of your query is determined. The meaning of the verb in your question can change the result of your inquiry.
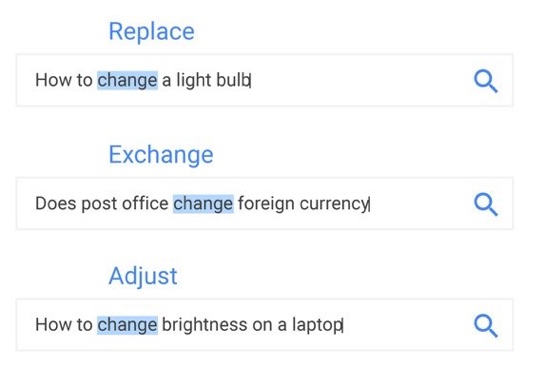
Also, how fresh is the information you seek? News will be on very new web pages while dictionary definitions can be on older sites.
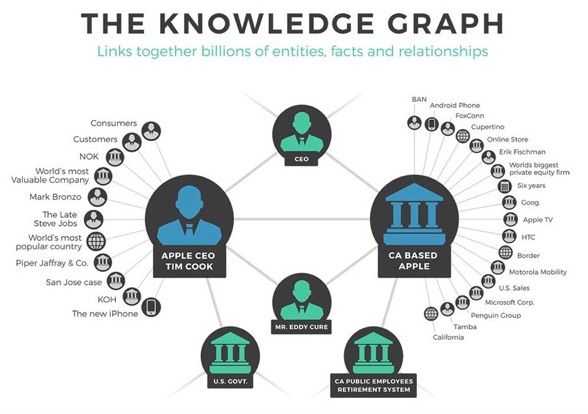
More than just searching strings of text, Google has assembled a “Knowledge Graph.”
The Knowledge Graph connects the relationships of people, places, things and facts.
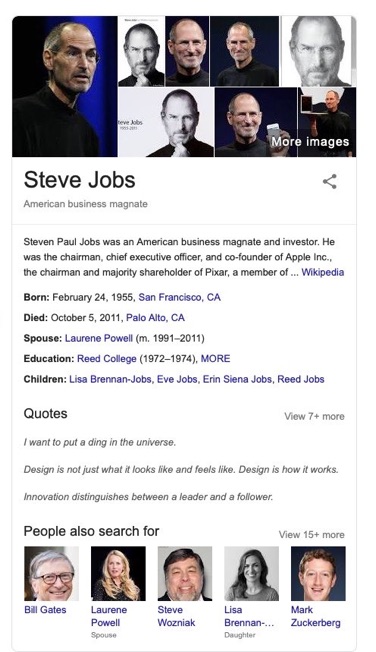
When you search for “Steve Jobs” you will see a summary including pictures, quotes, statistics and a biography. Links to relatives, institutions and places are included in this summary.
Google is not the Internet, but it has compiled and organized the Internet and molded it into mankind’s most useful reference tool.
Are you sure Google is not the internet? Well at least Wi-Fi must be the internet.